CLIP-Dissect Automatic Evaluation
| Hou Wan | hwan@ucsd.edu |
| Mentor: Lily Weng | lweng@ucsd.edu |
Overview
The CLIP-Dissect Automatic Evaluation framework is designed to provide deeper insights into the interpretability of deep neural networks. By leveraging multimodal vision/language models like BLIP-2 and OpenCLIP, this framework automates the process of associating neurons with conceptual labels. This method is particularly useful for analyzing hidden neurons, where ground-truth labels are not directly accessible, providing a structured alternative to manual evaluation methods.
Methodology
Our evaluation framework utilizes three distinct approaches to assess the relevance of neuron labels based on their top activating images:
-
BLIP-2 Prompting: This method employs a Visual Question Answering (VQA) model to evaluate whether activating images correspond to neuron labels. It prompts BLIP-2 with targeted yes/no questions about image-label alignment, offering a nuanced understanding of complex visual settings that closely mimics human evaluations.
-
OpenCLIP Concept Proportion: Using an open-source CLIP variant, this approach ranks image-text similarities and checks if the neuron label falls within a top proportion of ranked concepts. It provides a systematic way to evaluate how well a label matches a neuron’s activating images.
-
OpenCLIP Embedding Similarity: This method calculates the cosine similarity between embeddings of activating images and neuron labels, classifying matches based on a chosen similarity threshold. It is particularly effective for a rapid assessment of direct image-label alignment.
Key Findings
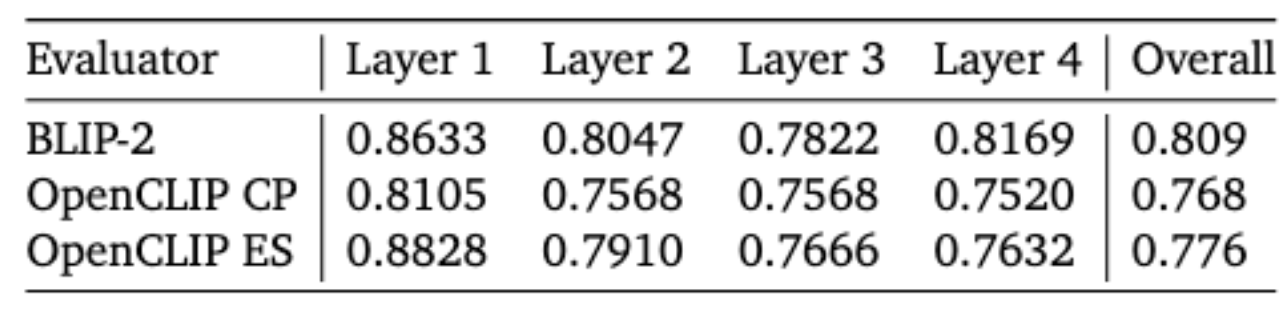
- Alignment with Human Judgments: BLIP-2 achieved the highest Intersection over Union (IoU) score of 0.809, indicating superior alignment with human evaluators. It captures subtle details that are often overlooked by other automated methods. The OpenCLIP methods, while less nuanced, performed solidly with IoUs of 0.768 (concept proportion) and 0.776 (embedding similarity), showing their value for more straightforward assessments.
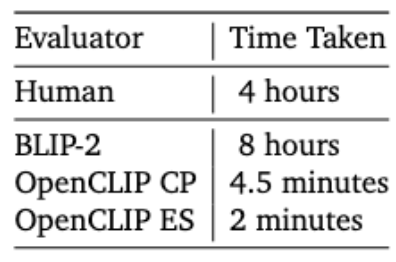
- Efficiency Considerations: A key trade-off exists between the depth of analysis and computational speed. BLIP-2 offers rich, detailed evaluations but requires around 8 hours of processing time. OpenCLIP methods excel in speed, completing evaluations in just 4.5 minutes (concept proportion) and 2 minutes (embedding similarity). These faster methods are particularly advantageous for large-scale analysis or time-sensitive projects.
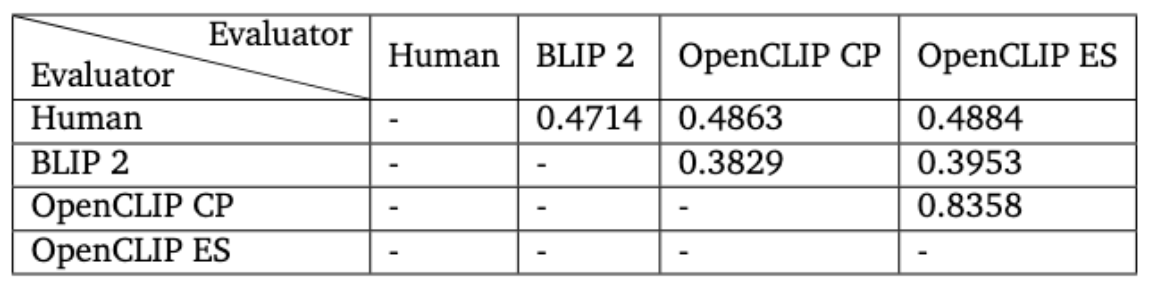
- Evaluation Consistency: The kappa statistic (κ) revealed a moderate agreement between BLIP-2 and human evaluations (κ = 0.4714), indicating a reasonable but imperfect alignment. OpenCLIP methods demonstrated substantial internal consistency (κ = 0.8358), but lower agreement with BLIP-2, reflecting their more binary approach to neuron labeling.
Discussion
Our findings reveal that while BLIP-2 excels in capturing the subtle, context-rich associations between images and neuron labels, it comes at the cost of longer evaluation times. In contrast, OpenCLIP methods, despite their more straightforward evaluation style, provide a rapid and reliable alternative. The choice between these methods depends on the specific needs of the analysis—BLIP-2 for in-depth, qualitative insights, and OpenCLIP for quick, large-scale evaluations.
The framework’s adaptability to newer models ensures it remains up-to-date with advancements in vision-language analysis. This flexibility is crucial for researchers seeking to refine the interpretability of neural networks without being constrained by older evaluation models.
Conclusion
The CLIP-Dissect Automatic Evaluation framework offers a robust, scalable solution for understanding how deep neural networks process information. By automating neuron labeling and leveraging state-of-the-art vision models, it minimizes the reliance on time-consuming manual evaluations. This framework not only verifies the accuracy of CLIP-Dissect’s neuron labels but also provides a valuable tool for improving neural network interpretability, supporting researchers in decoding the ‘black box’ nature of AI models.
Future Work
Moving forward, our focus will be on improving the adaptability of the framework to handle more complex datasets like ImageNet. The initial evaluations indicate that highly specific labels in ImageNet can challenge both human and automated evaluators. To address this, we aim to incorporate datasets featuring more general, intuitive concepts, such as basic shapes and common objects, to create a more human-aligned evaluation process.
Additionally, we plan to refine the threshold settings for OpenCLIP methods, aligning them more closely with human evaluative standards. These adjustments will help us further bridge the gap between automated and manual interpretations, making the evaluations more intuitive and reflective of human judgment.